Introduction
In this tutorial, we will cover all the necessary Python code that someone would need, in order to process hires that took place in the past and attempt to predict if a job applicant will get hired or not in the future.
Essentials
- Intermediate Python knowledge.
- Jupyter Notebook server installed.
- GraphViz installed (sudo apt-get install graphviz)
- Pydotplus (pip install pydotplus)
How To Predict Future Hires Using Decision Trees In Python
First, we’ll load some made-up data on past hires. We will use pandas to convert a CSV file into a DataFrame:
import numpy as np
import pandas as pd
from sklearn import tree
input_file = "PastHires.csv"
df = pd.read_csv(input_file, header = 0)And let’s take a quick look of the data loaded in the data frame:
df.head()Output:
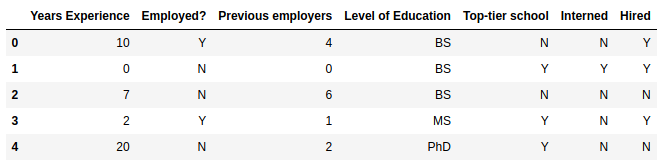
For Decision Trees to work properly, scikit-learn needs everything to be numerical. So, we’ll map Y, N to 1, 0 and levels of education to some scale of 0-2. In the real world, you would want to think about how to deal with unanticipated or missing data! By utilizing map(), we know that we will get NaN for unexpected values.
d = {'Y': 1, 'N': 0}
df['Hired'] = df['Hired'].map(d)
df['Employed?'] = df['Employed?'].map(d)
df['Top-tier school'] = df['Top-tier school'].map(d)
df['Interned'] = df['Interned'].map(d)
d = {'BS': 0, 'MS': 1, 'PhD': 2}
df['Level of Education'] = df['Level of Education'].map(d)
df.head()Output:
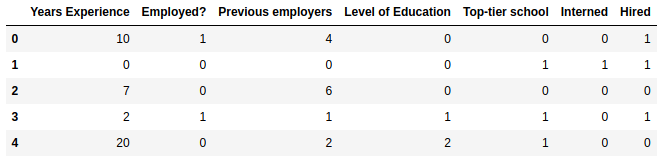
Next, we need to separate the features from the target column that we’re trying to build a decision tree for.
features = list(df.columns[:6])And now actually construct the decision tree:
y = df["Hired"]
X = df[features]
clf = tree.DecisionTreeClassifier()
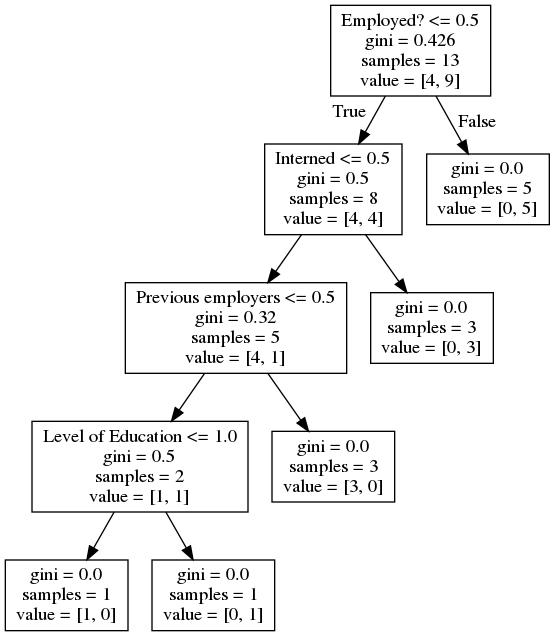
clf = clf.fit(X,y)To read this decision tree that we will generate shortly, each condition branches left for “True” and right for “False”. When you end up at a value, the value array represents how many samples exist in each target value. So value = [0. 5.] mean there are 0 “no hires” and 5 “hires” by the time we get to that point. The alue = [3. 0.] means 3 no-hires and 0 hires.
from IPython.display import Image
from sklearn.externals.six import StringIO
import pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=features)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())Output:
How To Predict The Employment Of Specific Candidate Profiles With Ensemble Learning
We’ll use a random forest of 10 decision trees to predict the employment of specific candidate profiles:
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, y)
#Predict employment of an employed 10-year veteran
print (clf.predict([[10, 1, 4, 0, 0, 0]]))
#...and an unemployed 10-year veteran
print (clf.predict([[10, 0, 4, 0, 0, 0]]))Output:
[1]
[1]
Which means that both candidates will be hired.
Predicting A Hiring Decision Using Apache Spark
First, we need to install Spark (if it’s not installed) executing
pip install pysparkThe python code is:
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.tree import DecisionTree
from pyspark import SparkConf, SparkContext
from numpy import array
# Boilerplate Spark stuff:
conf = SparkConf().setMaster("local").setAppName("SparkDecisionTree")
sc = SparkContext(conf = conf)
# Some functions that convert our CSV input data into numerical
# features for each job candidate
def binary(YN):
if (YN == 'Y'):
return 1
else:
return 0
def mapEducation(degree):
if (degree == 'BS'):
return 1
elif (degree =='MS'):
return 2
elif (degree == 'PhD'):
return 3
else:
return 0
# Convert a list of raw fields from our CSV file to a
# LabeledPoint that MLLib can use. All data must be numerical...
def createLabeledPoints(fields):
yearsExperience = int(fields[0])
employed = binary(fields[1])
previousEmployers = int(fields[2])
educationLevel = mapEducation(fields[3])
topTier = binary(fields[4])
interned = binary(fields[5])
hired = binary(fields[6])
return LabeledPoint(hired, array([yearsExperience, employed,
previousEmployers, educationLevel, topTier, interned]))
#Load up our CSV file, and filter out the header line with the column names
rawData = sc.textFile("PastHires.csv")
header = rawData.first()
rawData = rawData.filter(lambda x:x != header)
# Split each line into a list based on the comma delimiters
csvData = rawData.map(lambda x: x.split(","))
# Convert these lists to LabeledPoints
trainingData = csvData.map(createLabeledPoints)
# Create a test candidate, with 10 years of experience, currently employed,
# 3 previous employers, a BS degree, but from a non-top-tier school where
# he or she did not do an internship. You could, of course, load up a whole
# huge RDD of test candidates from disk, too.
testCandidates = [ array([10, 1, 3, 1, 0, 0])]
testData = sc.parallelize(testCandidates)
# Train our DecisionTree classifier using our data set
model = DecisionTree.trainClassifier(trainingData, numClasses=2,
categoricalFeaturesInfo={1:2, 3:4, 4:2, 5:2},
impurity='gini', maxDepth=5, maxBins=32)
# Now get predictions for our unknown candidates. (Note, you could separate
# the source data into a training set and a test set while tuning
# parameters and measure accuracy as you go!)
predictions = model.predict(testData)
print('Hire prediction:')
results = predictions.collect()
for result in results:
print(result)
# We can also print out the decision tree itself:
print('Learned classification tree model:')
print(model.toDebugString())